42 in supervised learning class labels of the training samples are known
Time Series Forecasting as Supervised Learning 14.08.2020 · Take a look at the above transformed dataset and compare it to the original time series. Here are some observations: We can see that the previous time step is the input (X) and the next time step is the output (y) in our supervised learning problem.We can see that the order between the observations is preserved, and must continue to be preserved when using this … Machine learning - Wikipedia Machine learning (ML) is a field of inquiry devoted to understanding and building methods that 'learn', that is, methods that leverage data to improve performance on some set of tasks. It is seen as a part of artificial intelligence.Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly ...
PHSchool.com Retirement–Prentice Hall–Savvas Learning … Online Program Samples; Store Home; Sign In. Savvas Realize™ my Savvas Training; Savvas EasyBridge; Savvas SuccessNet; Online Samples; Customer Care . Savvas Learning Company > PHSchool.com; Prentice Hall PHSchool.com PHSchool.com Retirement Notice . Due to Adobe’s decision to stop supporting and updating Flash ® in 2020, browsers such as Chrome, Safari, …

In supervised learning class labels of the training samples are known
Supervised learning - Wikipedia A first issue is the tradeoff between bias and variance. Imagine that we have available several different, but equally good, training data sets. A learning algorithm is biased for a particular input if, when trained on each of these data sets, it is systematically incorrect when predicting the correct output for .A learning algorithm has high variance for a particular input if it predicts ... API Reference — scikit-learn 1.1.3 documentation API Reference¶. This is the class and function reference of scikit-learn. Please refer to the full user guide for further details, as the class and function raw specifications may not be enough to give full guidelines on their uses. For reference on concepts repeated across the API, see Glossary of Common Terms and API Elements.. sklearn.base: Base classes and utility functions¶ Learning with not Enough Data Part 1: Semi-Supervised Learning 05.12.2021 · When facing a limited amount of labeled data for supervised learning tasks, four approaches are commonly discussed. Pre-training + fine-tuning: Pre-train a powerful task-agnostic model on a large unsupervised data corpus, e.g. pre-training LMs on free text, or pre-training vision models on unlabelled images via self-supervised learning, and then fine-tune it …
In supervised learning class labels of the training samples are known. Supervised and Unsupervised Machine Learning Algorithms 15.03.2016 · You can also use supervised learning techniques to make best guess predictions for the unlabeled data, feed that data back into the supervised learning algorithm as training data and use the model to make predictions on new unseen data. Summary. In this post you learned the difference between supervised, unsupervised and semi-supervised ... Introduction to Supervised Learning - GitHub Pages 03.02.2020 · class: center, middle ### W4995 Applied Machine Learning # Introduction to Supervised Learning 02/03/20 Andreas C. Müller ??? Hey everybody. Today, we’ll be talking more in-dep A survey on semi-supervised learning | SpringerLink 15.11.2019 · Semi-supervised learning is the branch of machine learning concerned with using labelled as well as unlabelled data to perform certain learning tasks. Conceptually situated between supervised and unsupervised learning, it permits harnessing the large amounts of unlabelled data available in many use cases in combination with typically smaller sets of … 14 Different Types of Learning in Machine Learning 11.11.2019 · Machine learning is a large field of study that overlaps with and inherits ideas from many related fields such as artificial intelligence. The focus of the field is learning, that is, acquiring skills or knowledge from experience. Most commonly, this means synthesizing useful concepts from historical data. As such, there are many different types of learning that you may …
Learning with not Enough Data Part 1: Semi-Supervised Learning 05.12.2021 · When facing a limited amount of labeled data for supervised learning tasks, four approaches are commonly discussed. Pre-training + fine-tuning: Pre-train a powerful task-agnostic model on a large unsupervised data corpus, e.g. pre-training LMs on free text, or pre-training vision models on unlabelled images via self-supervised learning, and then fine-tune it … API Reference — scikit-learn 1.1.3 documentation API Reference¶. This is the class and function reference of scikit-learn. Please refer to the full user guide for further details, as the class and function raw specifications may not be enough to give full guidelines on their uses. For reference on concepts repeated across the API, see Glossary of Common Terms and API Elements.. sklearn.base: Base classes and utility functions¶ Supervised learning - Wikipedia A first issue is the tradeoff between bias and variance. Imagine that we have available several different, but equally good, training data sets. A learning algorithm is biased for a particular input if, when trained on each of these data sets, it is systematically incorrect when predicting the correct output for .A learning algorithm has high variance for a particular input if it predicts ...
Self-supervised, semi-supervised, and multi-view learning ...
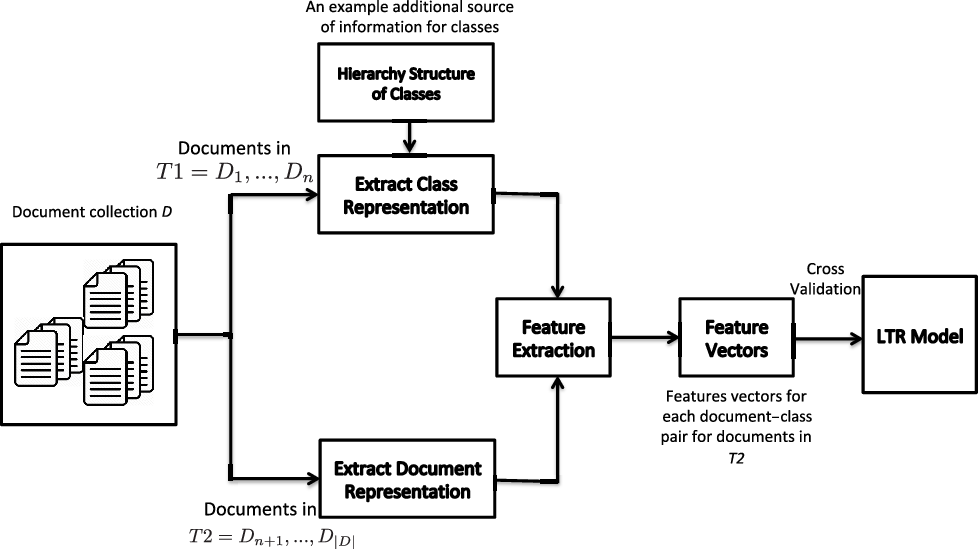
Learning to rank for multi-label text classification ...
A Survey on Deep Semi-supervised Learning

Data Labeling | Data Science Machine Learning | Data Label
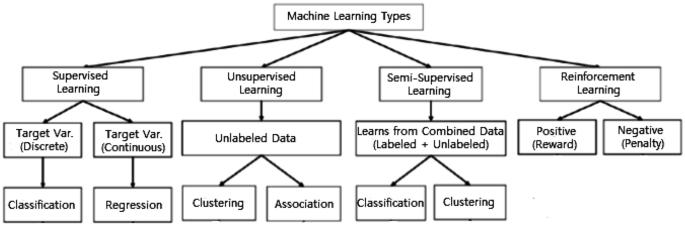
Machine Learning: Algorithms, Real-World Applications and ...

Solved Section VI: Miscellaneous - Each question carries 2 ...

Extending Contrastive Learning to the Supervised Setting ...

What is Supervised Learning? | TIBCO Software

Supervised Classification - an overview | ScienceDirect Topics
![Supervised vs. Unsupervised Learning [Differences & Examples]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/6158dd5a5c04109f63363e0a_67KbBrP_mJMkcaOsEOlrk5eedzXJolEg5wkJX8nQLiarNAClBP0q5XncPyQM7jyoGKUGsc_onAJnBkVDfEkKVWIFNuZYZmaWq1hkP1fIQwX4nQMoDulaNYCkJvVgHr6IZOYdc5rv%3Ds0.png)
Supervised vs. Unsupervised Learning [Differences & Examples]

Supervised Machine Learning - an overview | ScienceDirect Topics
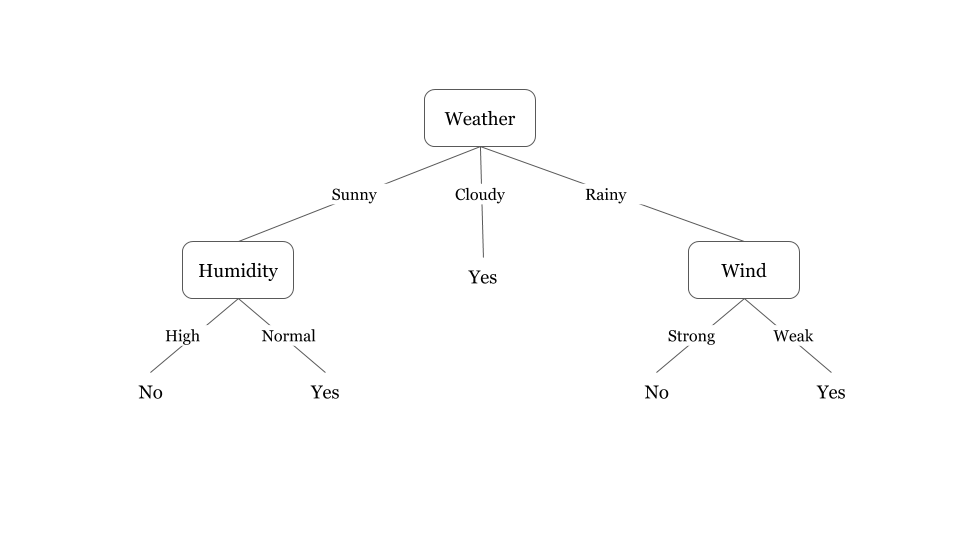
Decision Tree Tutorials & Notes | Machine Learning | HackerEarth

Unsupervised Machine Learning - an overview | ScienceDirect ...

Supervised Learning - an overview | ScienceDirect Topics
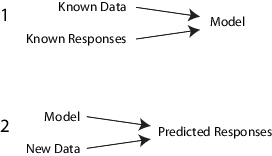
Supervised Learning Workflow and Algorithms - MATLAB & Simulink
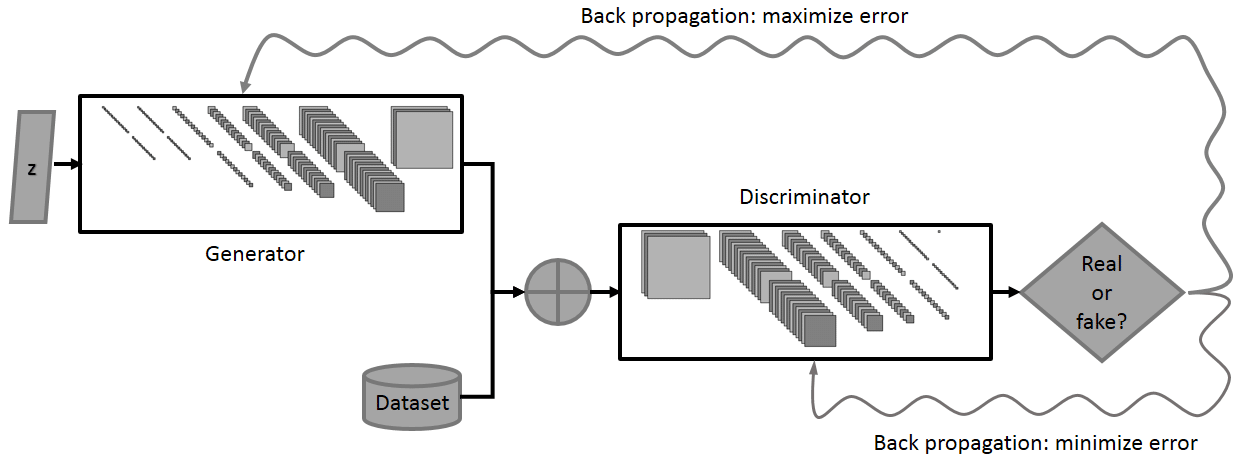
Difference Between Supervised, Unsupervised, & Reinforcement ...

A Personal Tour of Machine Learning and Its Applications ...
Solved] A summary covering the following topic:. Why ...
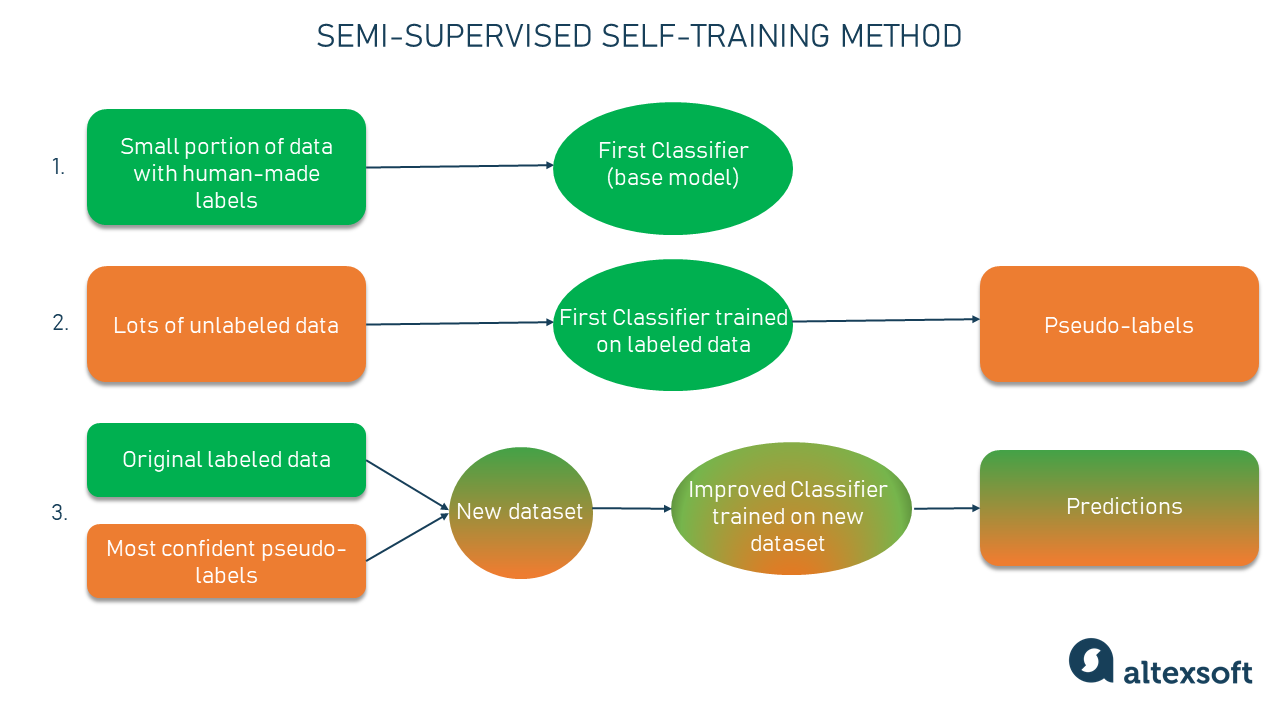
Semi-Supervised Learning, Explained | AltexSoft

Unstructured Data Classification.txt - In Supervised learning ...

Self-Supervised Learning and Its Applications - neptune.ai
![Supervised vs. Unsupervised Learning [Differences & Examples]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/627d12509bceec03c52a4feb_616b63f3b531b95ff6a35dea_data-in-supervised-vs-unsupervised-cover.png)
Supervised vs. Unsupervised Learning [Differences & Examples]
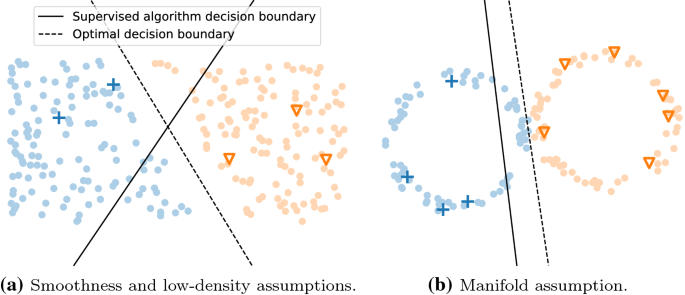
A survey on semi-supervised learning | SpringerLink

PDF) Generalized Discussion over Classification Algorithm ...

Supervised and Unsupervised Machine Learning Algorithms

A Cluster-then-label Semi-supervised Learning Approach for ...
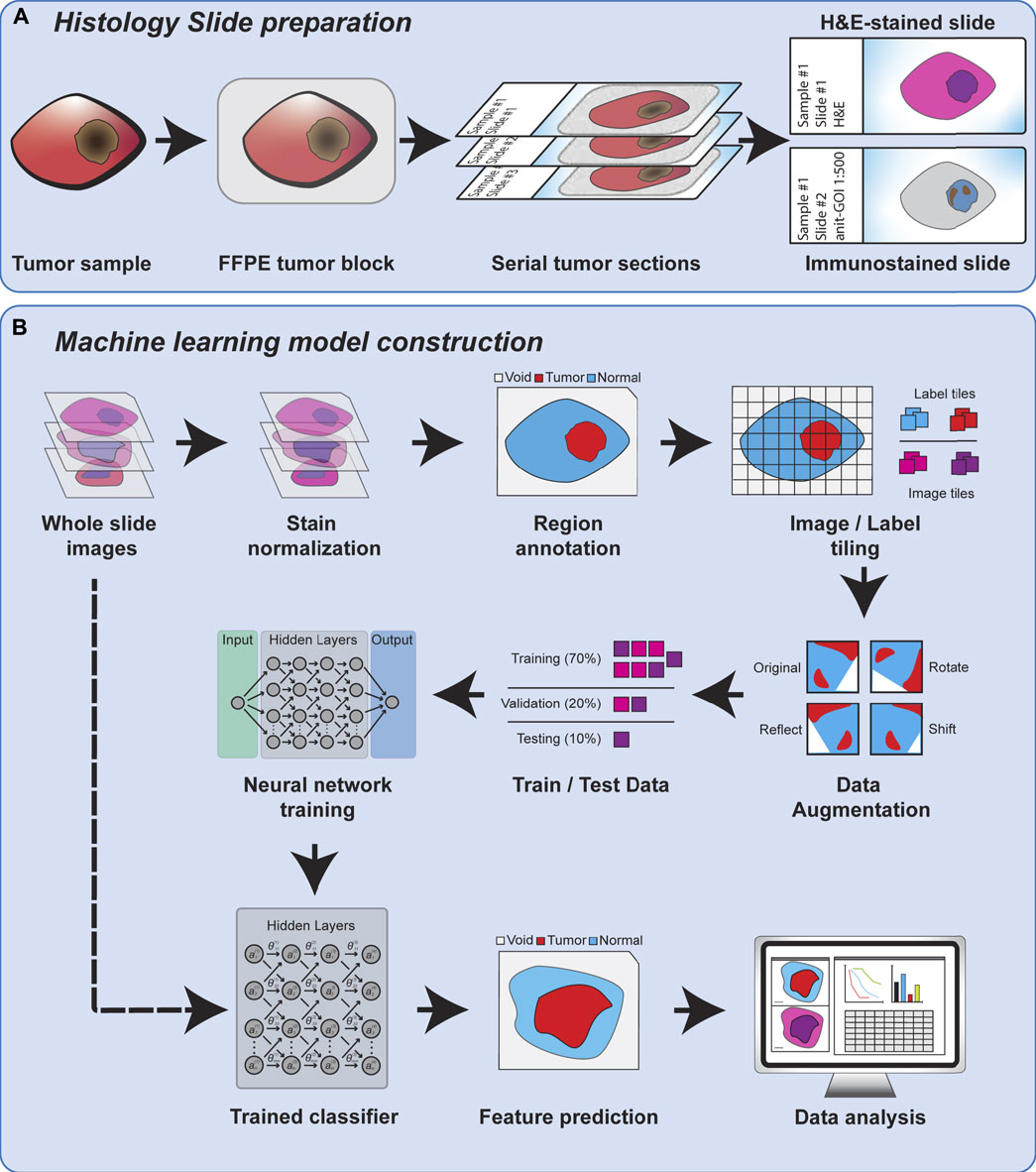
Frontiers | Deep Learning of Histopathology Images at the ...
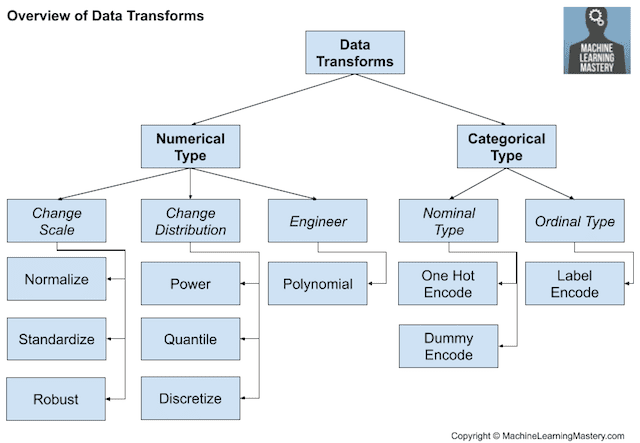
14 Different Types of Learning in Machine Learning
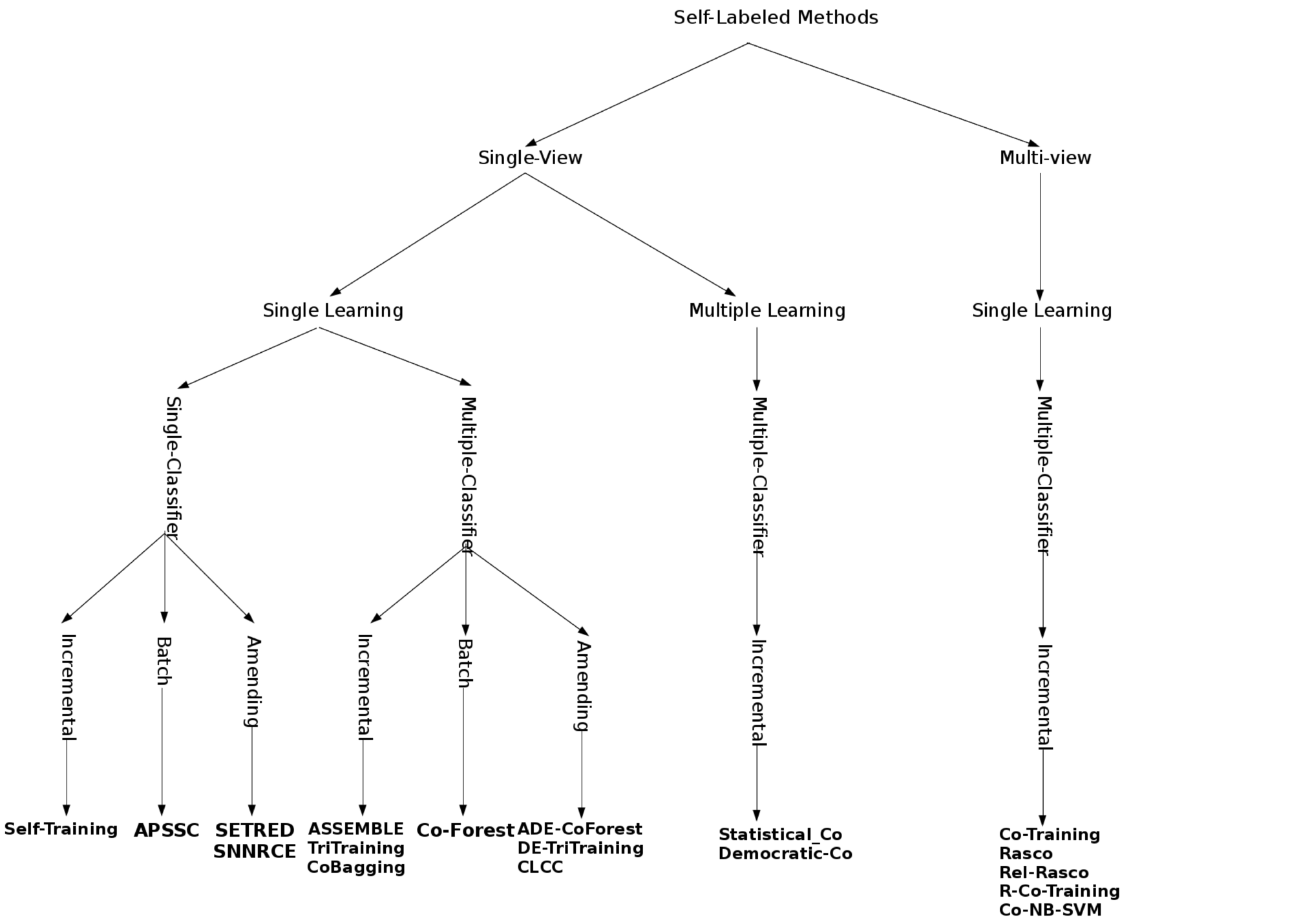
Semi-supervised Classification: An Insight into Self-Labeling ...
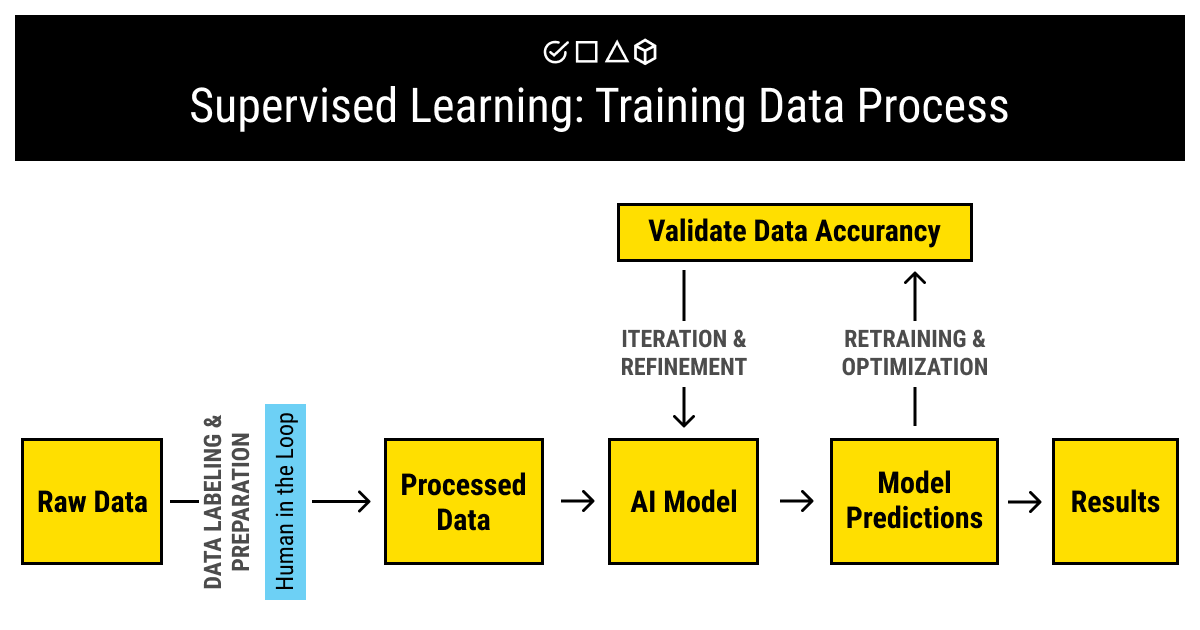
Machine Learning & Training Data: Sources, Methods, Things to ...
Self-Updating Models with Error Remediation
Introduction to Machine Learning 1 Supervised Learning
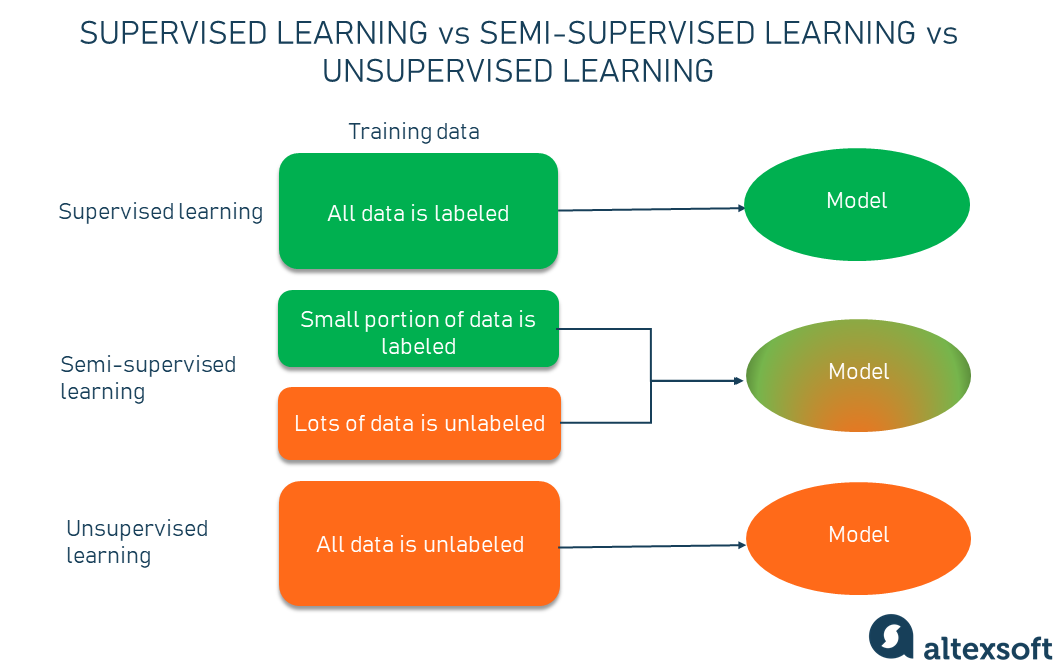
Semi-Supervised Learning, Explained | AltexSoft

Classification in Machine Learning: What it is and ...

Supervised Learning With Python: What to Know | Built In
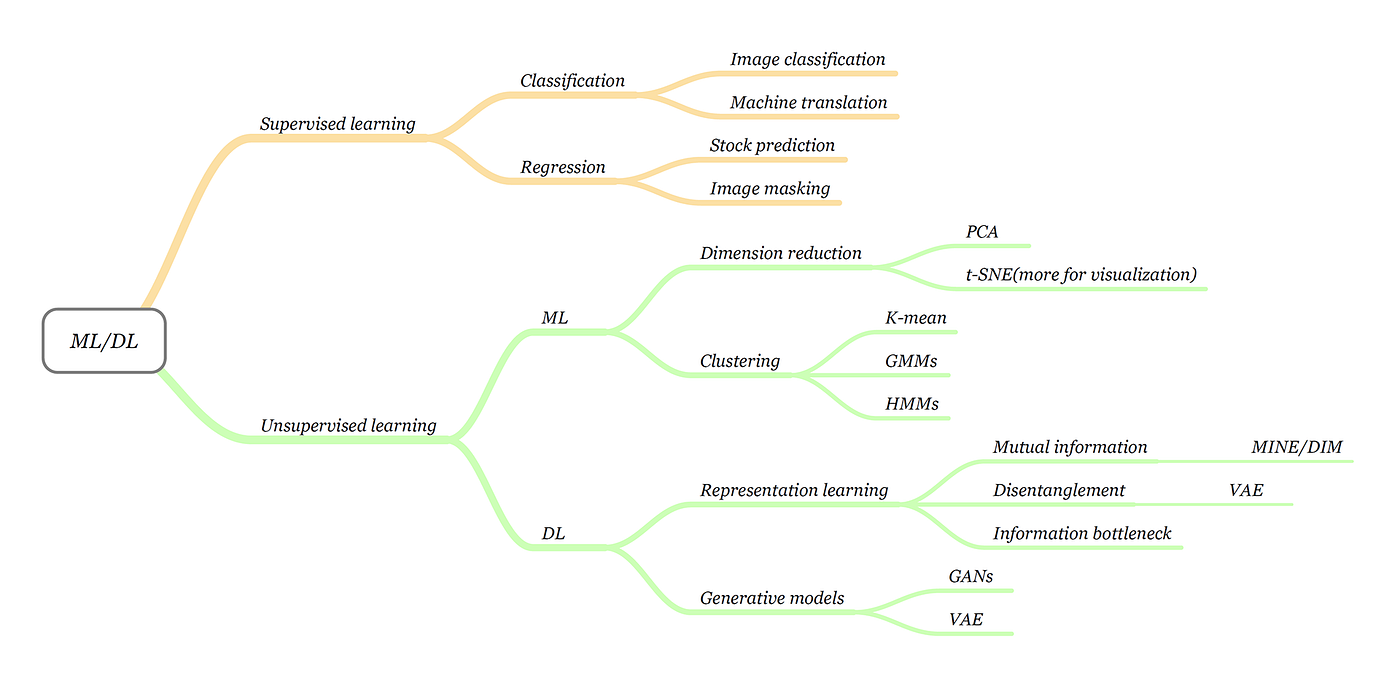
Machine Learning Algorithms For Beginners with Code Examples ...
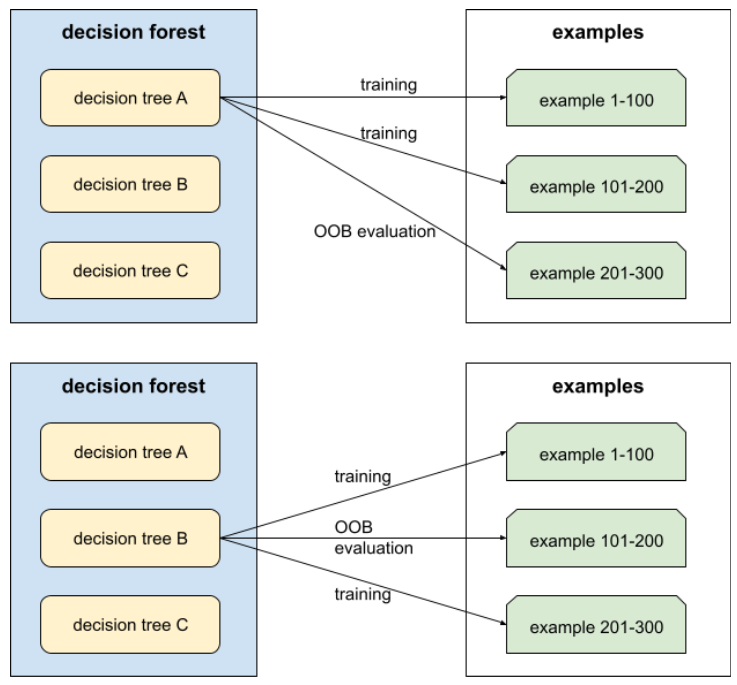
Machine Learning Glossary | Google Developers
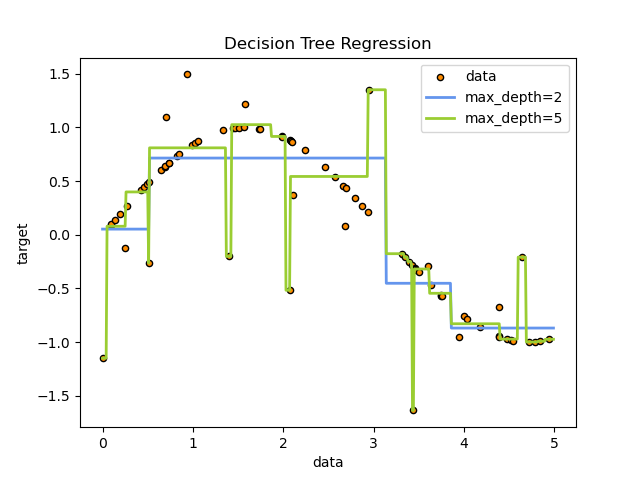
1.10. Decision Trees — scikit-learn 1.1.3 documentation
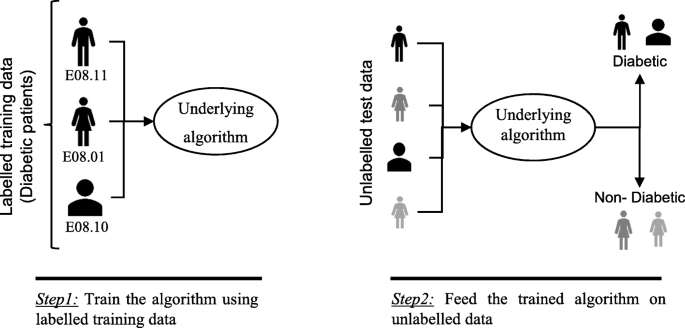
Comparing different supervised machine learning algorithms ...
![What Is Data Labelling and How to Do It Efficiently [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/60d9ab454dc7ad70f8c5d860_supervised-learning-vs-unsupervised-learning.png)
What Is Data Labelling and How to Do It Efficiently [2022]
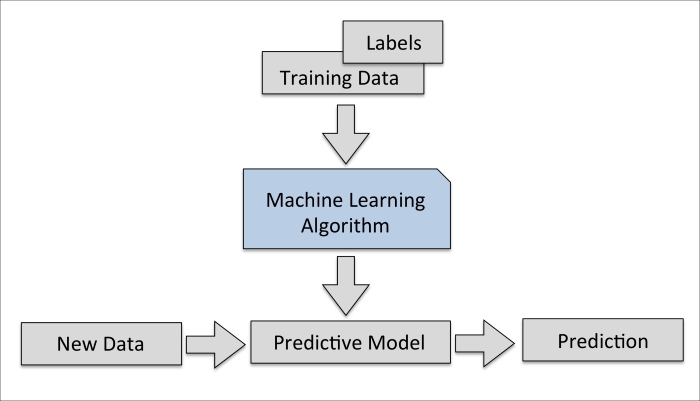
The three different types of machine learning | Python ...
An overview of proxy-label approaches for semi-supervised ...
Post a Comment for "42 in supervised learning class labels of the training samples are known"